1. What is TF Hub? How did you use it when creating your script for “text classification of movie reviews”?
- TF Hub is a library in TensorFlow that allows for the reusability of machine learning models. This reuse is useful in transfer learning, which involves training models on a smaller segment of the data and reusing the information gathered from this training to not only improve upon the current model, but also to apply this to another similar problem. The concept of transfer learning is similar to the concept of learning how to run. You first start small by learning how to crawl, then you gradually build on this knowledge to learn how to walk, and then you gradually build on this knowledge to gain more and more speed until you’re running. I used TF Hub when creating my script to classify text frpm IMDB movie reviews by building a neural network with a pre-trained text embedding model in the first layer of the network. This pre-trained text embedding model (google/tf2-preview/gnews-swivel-20dim/1) has a set embedding size equal to (# of examples, 20 dimensions), and also handles preprocessing of the text data by splitting the input at blank spaces. Plus, it comes with the added advantage of transfer learning. It was specifically used to embed the text from the movie reviews by splitting the sentence into individual embedded tokens, which were then combined into one embedded sentence.
2. What are the optimizer and loss functions? How good was your “text classification of movie reviews” model?
-
Similar to my model for clothing classification from July 8, this model for movie review text classification utilizes the “adam” optimizer function. I attached a link to an article that does a nice job explaining this function in futher detail in the response from July 8, but the “adam” optimizer operates by adapting the model’s learning rate. My model for text classification of movie reviews uses the “binary_crossentropy” loss function to minimize the distance between the probability distributions of the actual classifications and the predicted classifications. By selecting a binary loss function, I am seeking to classify the movie reviews’ text as one of two options - either positive or negative. As such, the “binary_crossentropy” loss function will seek to minimize the distance between the probability that a movie review is actually positive or negative and the model’s confidence that the movie review is positive or negative. I found an article that gives a helpful description of this particular loss function: Binary Cross Entropy Loss Description.
My model for the text classification of movie reviews did quite well, with a rather high classification accuracy of approximately 0.85 and a rather low loss of approximately 0.32. However, the model could be better, because a lower loss indicates more accurate predictions.
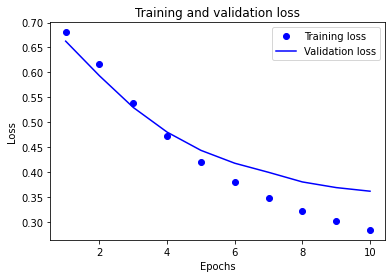
3. In “text classification with preprocessed text” you produced a graph of training and validation loss. Add the graph to this response and provide a brief explanation.
-
The graph below displays the loss for both the training and validation/testing datasets over time. In the case of neural networks, time refers to the number of epochs. The training loss is depicted as a dotted blue line, while the validation loss is depicted as a solid blue line. Both decline as the number of epochs increases, which shows that as the model makes more “guesses”, the model becomes more accurate in predicting a movie review as positive or negative. However, there is a subtle difference between the training and validation loss over time. At around the fourth epoch, the validation loss decreases more than the training loss. This indicates that the model is overfit to the training data and is, therefore, not as accurate at predicting the text classification of other movie reviews outside of the training set. Thus, to prevent overfitting the model, it would be most optimal to train with up to, but no more than, four epochs. It will be important to see the accuracy over time to confirm that this is the best decision.
The lowest training loss occurred at ten epochs and was approximately 0.275. If selecting four epochs to prevent overfitting, the training loss would be about 0.475. Likewise, the lowest validation loss occurred at ten epochs and was approximately 0.375. If selecting four epochs, the validation loss would be similar to the training loss, at about 0.475.
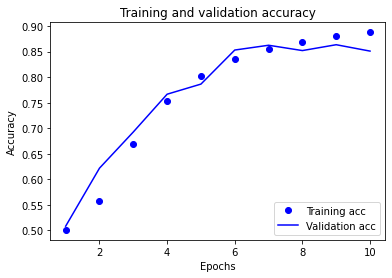
4.Likewise do the same for the training and validation accuracy graph.
-
The graph below displays the accuracy for both the training and validation datasets over time. Similar to the loss graph above, the training accuracy is depicted as a dotted blue line, while the validation accuracy is depicted as a solid blue line, across the number of epochs used. Both increase as the number of epochs increases, which follows from the loss graph. As the loss decreases, accuracy increases. Interestingly, the validation accuracy curve is not as smooth as the corresponding validation loss curve, or even the training accuracy curve. I thought this was surprising to see, since the validation accuracy should follow very closely, but in an inverse relationship, with the validation loss. At around the fifth epoch, and again after the seventh, the training accuracy is greater than the validation accuracy. This confirms what the loss graph indicated - the model is overfit to the training data. This helps to validate my suggestion that training the model with up four epochs is most optimal for valid/accurate predictions about the classification of text from IMDB movie reviews. However, the downside of only using four epochs is that the validation accuracy is not maximized.
The highest training accuracy occurred at ten epochs and was just below 0.90. If selecting four epochs to prevent overfitting, the training accuracy would be about 0.775. The highest validation accuracy did not occur at the same time as the highest training accuracy. Instead, the highest training accuracy occurred at either 7 or 9 epochs, and was slightly above 0.85. If selecting four epochs, the validation accuracy would be similar to the training accuracy, at about 0.775.